Splitting User Stories Across Teams

I recently received a question by email wondering if large user stories should be split across teams. The question was so interesting that I thought I would summarize my response here.

Sometimes large user stories are broken down into smaller stories that are tackled by multiple teams. For example, imagine that your organization has two teams: a team that owns your web application and a team that owns your mobile application. If you are releasing a feature across both platforms you may originally start with that feature described as a single user story but then split the story in two as each team tackles their respective implementations.When multiple teams work on a single product we like to keep a single Product Backlog that all teams share. This lets the Product Owner see the big picture at any given time which helps keep them focused on the overall vision for the product.
Even if a larger story that will ultimately be split across several teams we tend to keep it as a single story during the Product Backlog phase. This helps to prevent us from getting mired in the weeds of each story too early and makes the story easier to move up and down the backlog as new priorities emerge.
Keeping the story as a single unit also it makes it easier to assign an estimate to. Admittedly, we know that the estimate won't be as accurate as if we broke the story down and estimated each individual part, but that's ok. We accept that estimates are less reliable during this stage and only use them for getting an idea of the complexity of a story relative to other stories in the backlog.
Splitting User Stories During Sprint Planning
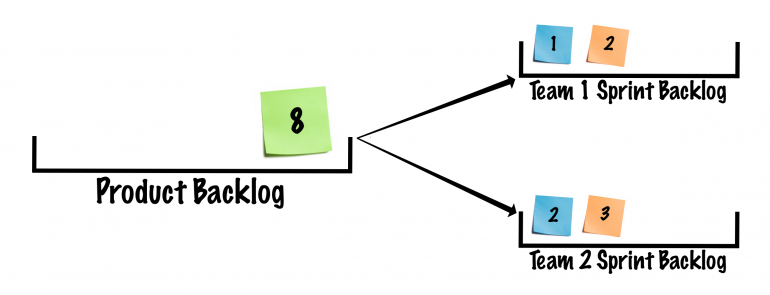
However, during Sprint Planning the top stories in the product backlog are moved into a separate Sprint Backlog for each team. At this point those same large stories are broken down and split into separate stories for each team, who then take this opportunity to estimate their individual portions. The sum of those estimates may add back up to match the original estimate of the large story, but don't be surprised if they don't. Breaking larger stories down into smaller stories often tends to expose gaps that we didn't originally consider when the story was in its larger form, so new stories may emerge as a result.
Allowing each team to work from their own Sprint Backlog minimizes the number of dependencies each team needs to complete their work. We want each team to have as many of the skills as possible to complete a valuable increment of the product during each sprint, which is one of the reasons why we strive to make scrum teams cross-functional. If a team can still deliver a valuable increment themselves, then we want that work split only into the portion that they can complete.In addition, Velocity is our primary planning metric in scrum. Teams who estimate in story points eventually start to evolve those points to the range that makes the most sense for each team. Put another way, a story point for one team may be wildly different than a story point for another team. This flexibility is what gives story points their power as each team starts to assign the most accurate value to each point that makes sense to them.
The side effect of this, however, is that the Velocity of two different teams can start to vary wildly even if each team is completing roughly the same amount of work. For this reason we want to be able to map a separately velocity to each team which better represents the amount of work they're completing during a sprint rather than trying to roll all velocities into a single number. This gives us a more accurate representation of how much each team tends to complete during each sprint, which lets us plan the overall product even better.